
Building cold-email-1: What We Learned From Training a Small Model to Outperform the Big Ones
Robin Salimans
May 21, 2025
Today we release cold-email-1, a small language model fine-tuned specifically for writing outbound sales emails. It's part of a broader bet we're making at Utopian Labs: that highly focused, task-specific models can outperform general-purpose ones - not by being bigger, but by being better at a narrow job.
In this post, we’ll share how we trained the model, what went wrong along the way, how we measured success, and how we managed the trade-offs between competing goals like readability, relevance, and factual accuracy. We used a combination of synthetic data generation, filtering, and reinforcement learning with a few tweaks of our own.
If you’re into practical ML, RL, or just curious how you can get real performance out of smaller models, this might be useful.
Step 1: Data Generation and Filtering for Cold Start Fine-Tuning
Before we could do any reinforcement learning, we needed a solid starting point. For the initial cold start fine-tuning run, we generated a large amount of task-specific data, scored it across multiple dimensions, and only kept the best examples.
We selected a wide range of companies and people from public sources to simulate realistic outbound scenarios, then used our research + copywriting agent to generate over 300,000 cold emails, and then changed any real names (and other potentially personal identifiable information) to fake data for privacy reasons.
To filter this down, we applied a set of automated checks:
- Readability: We used Flesch Reading Ease to prioritize emails that were clear and easy to follow.
- Whitespace and length: Long walls of dense text were penalized. The ideal cold email is short and uses lots of whitespace.
- CTA strength: Ideally, a cold email has one clear call-to-action (not multiple questions) to which you can answer with 'yes' or 'no', and it should not ask for a meeting unless specifically instructed by the sender. This was judged by an LLM.
- Profanity: Score judged by an LLM, which would be 1 if no profanity was found, and 0 if profanity was found.
- Coherence: LLM-as-a-judge score, which checks whether the flow of the email is logical.
- Recipient focus: We measured the ratio of 'you' to 'I' to reward writing that centered the recipient rather than the sender.
- Spam language: Anything stuffed with obvious trigger words (e.g., 'free', 'buy now', 'make money', '$$$') was removed.
- Hallucinations: We used an LLM to check every sentence of the email outputs to see whether the claims made in the emails were grounded in the input information.
- Correct sign-off: We checked whether the sender's name was used in the email sign-off, and if no sender name was given, whether the sign-off was left out entirely.
- Instruction following: In a subset of the emails, we instructed the copywriting agent to include a meeting link, include a specific CTA, or added specific instructions about the email structure or contents. We then used an LLM to judge whether the instruction was followed.
- Grammar and spelling: We ran an LLM on the emails to spot any spelling or grammar errors, and deprioritised the emails that contained some.
- Presence of unfilled variables: If you've used LLMs to write emails before, you may notice that LLMs often end emails with '[First Name]', or start with 'Hi [Name],'. We flagged emails that included variables like this and filtered them out.
- Usage of links: Using links is a big no-no in cold emails. Therefore, unless the copywriting agent was specifically instructed to include a link in the email, emails with links were filtered out.
The most important filter was relevance. We used an LLM as a judge, scoring each email against a 15-point checklist that included things like:
- Is this a pitch slap, or is the email actually tailored to the recipient?
- Are we simply using a generic compliment as an opener, or are we actually making a relevant observation that is related to why your product is relevant for them?
- To what extent does the email show understanding of the recipient's world, and did we use the research report provided in an optimal way?
We took the top ~3% of emails across all metrics—about 10,000 samples—and used them to fine-tune our base model.
Step 2: Fine-Tuning and Reinforcement Learning
We started with a Qwen-3 4B base model: large enough to be capable, but small enough to run efficiently and fine-tune quickly. After filtering the 10k high-quality emails, we fine-tuned the base model to give it a solid understanding of good cold outreach.
That already got us decent results. But the real performance gains came from reinforcement learning.
We used a method inspired by DeepSeek’s Group Relative Policy Optimization (GRPO), where the model learns not from a single absolute score, but from comparisons between its own generations. The idea is: given a set of outputs, learn which ones are better and use that to improve.
DeepSeek showed in their already famous R1 paper that GRPO works very well when training on tasks that have a single correct and verifiable answer, like math or physics problems. Since our model writes cold emails and doesn't solve math problems, we didn't have the luxury of being able to determine whether the model's answer was correct or incorrect. We therefore needed to come up with a new way of determining the quality of a model's output.
We ended up creating multiple reward functions; some of which scored deterministically, some judged by LLMs, and some a combination of both:
- Readability (based on Flesch score again)
- Structure (combination of word count, whitespace, correct CTA, proper sign-off scores)
- Quality (combination of coherence, hallucinations, avoidance of spam words, avoidance of unfilled variable scores)
- Instruction following, judged by an LLM like before
- Relevance, scored by an LLM using the same 15-point checklist we used earlier
At first, we tried optimizing for everything at once. That gave us improvements in surface-level metrics: emails were shorter, easier to read, and used proper CTAs. But relevance plateaued.

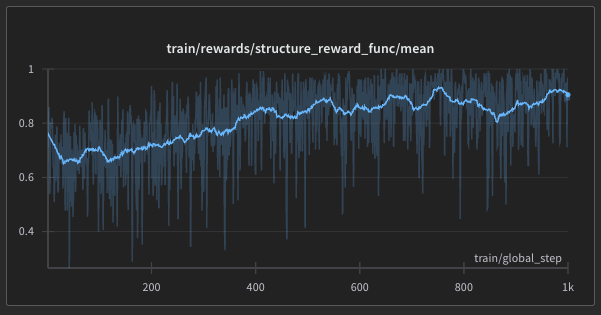
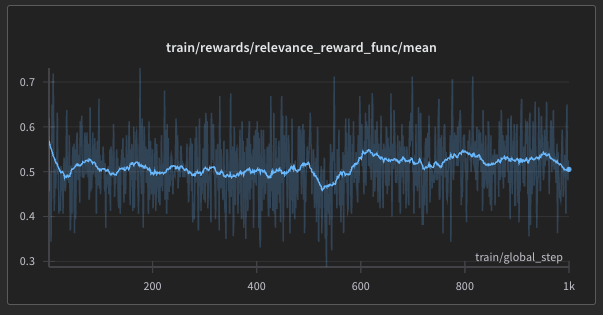
So we changed tactics.
We ran a second reinforcement learning phase focused only on relevance. That worked: emails became significantly more targeted and thoughtful.
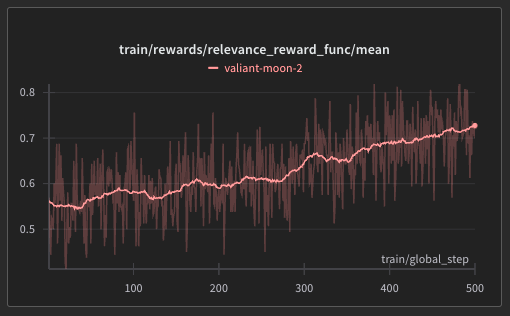
But we started seeing some hallucinations: the model would occasionally make things up to sound more relevant.
To fix that, we adjusted our training to always favor factual accuracy. This brought the relevance score down slightly (from ~0.75 to ~0.65), but made the outputs more trustworthy.
In the final (third) RL run, we reintroduced the other metrics and aimed for balance. We did this because increasing relevance actually decreased readability, instruction following, and increased word count.
To our surprise, when reintroducing the other rewards, all other rewards improved to previous levels (and further), whilst relevance stayed at the ending level of the run where we focused on relevance.
This gave us a model that was:
- Relevant, but not hallucinating
- Easy to read, but still had depth
- Focused on the recipient, not just generic pitches
This multi-pass RL approach turned out to be the key to breaking out of local optima and actually improving the model across all dimensions.
Step 3: Fixing Weird RL Artifacts with One Last Fine-Tune
Reinforcement learning gave us strong improvements in relevance and overall quality, but it also introduced some quirks.
The model had learned to game certain reward metrics. For example, it figured out that phrases like "juggling X and Y" or "you must be eyeing X" helped boost readability and recipient focus scores. So it started using them everywhere. Every email was suddenly about juggling or eyeing something. It read well on paper, but didn’t sound natural at all.
To fix this, we generated a new dataset:
- For each sender-receiver pair, we generated 10 email variants using the RL-tuned model.
- We picked the best one using our scoring functions (relevance, readability, recipient-focus, etc.).
- We manually edited a batch of 3,000 emails, cleaning up artifacts and making the language more varied and human again.
We then did a final supervised fine-tuning (SFT) run on this cleaned dataset. This last step helped bring the model back to a more natural style, while keeping all the gains from RL intact.
This was also a good reminder that reward functions, no matter how thoughtful, can still be gamed. A bit of cleanup at the end went a long way.
Step 4: Evaluation and Transparency
Once we had a model we were happy with, the next question was: how do we actually know it's good?
We didn’t want to rely on vague impressions or cherry-picked examples, so we evaluated cold-email-1 the same way we trained it: by running it through a structured checklist of real-world criteria. For relevance, we reused the same LLM-based judge with the 15-point framework. For judging the quality of CTAs, we used LLM-as-a-judge as well. For everything else (readability, word count, whitespace, etc.), we used deterministic scoring.
At Utopian Labs, one of our top priorities is reliability at scale. In the world of cold email, inconsistent output quality is a common problem; especially with general-purpose LLMs. Users often get burned after just a few tries when the model produces one good email and nine bad ones. We believe that consistently high-quality output, even across thousands of variations, is one of the biggest barriers to broader adoption. Solving that is core to why we’re building hyper-specialized models in the first place.
To make sure we weren’t overfitting to our own taste, we:
- Held back a set of evaluation prompts and targets that were never seen during training
- Compared cold-email-1 outputs side-by-side with outputs from general-purpose models (including GPT-4.1, GPT-4o, Claude 3.7 Sonnet, Grok 3, and Gemini 2.5 Pro)
- Gave early access to select partners and gathered feedback on real-world performance
We also wanted others to be able to validate the model’s performance, not just take our word for it. So we:
- Open-sourced part of our evaluation set, so everyone can run the same tests
- Released a free public scoring endpoint, so anyone can input a cold email and see how it would have been judged during training
- And, of course, wrote this technical blog post so that others can verify our methods on their own.
The goal is to be transparent, not just about what the model can do, but also where it might fail.
What’s Next
cold-email-1 is available now via API (on request) or as part of our R1-Copywriting agent that plugs directly into CRMs and workflow builders. Whether you're integrating it into your own stack or using it through our tools, the idea is the same: better emails, fewer generic blasts, and full control over the message.
We’re also releasing a public scoring endpoint, so you can evaluate your own cold emails using the same framework we trained on.
This is just the first in a series. We’re working on more hyper-specialized models - each trained for a very specific task, each small enough to run efficiently, and each evaluated against real-world performance (not just benchmarks). We think there’s a lot of value in models that are narrow but deep.
If you’re curious about trying it out, experimenting, or building something on top, we’d love to hear from you.